My Two Cents on Postgres Isolation Levels
tldr
- PostgreSQL is awesome
- read committed takes a new snapshot for every SQL statement
- repeatable read only has one snapshot
- repeatable read fails when the row it tries to modify was changed by other transactions
- repeatable read hang -> wakeup -> dies when the row of the lock it’s waiting is updated by other transactions
- serializable == repeatable read + serializable snapshot isolation
- serializable handles read write cases
- transactions are nodes in precedence graph
- t1 reads row1 and t2 writes row1 means t1 -> t2 in the precedence graph
- PostgreSQL serializable is optimistic
Overview
I always had a vague understanding of database isolation levels, recently I discovered that I had a major misunderstanding of it. I talked to Gemini for hours and “I think” I got it. This post is to verify that I actually got it with examples.
This post is specific for PostgreSQL.
When you go to the official PostgreSQL Transaction Isolation documentation it throws a lot of concepts to you and (at least for me) it was very confusing.
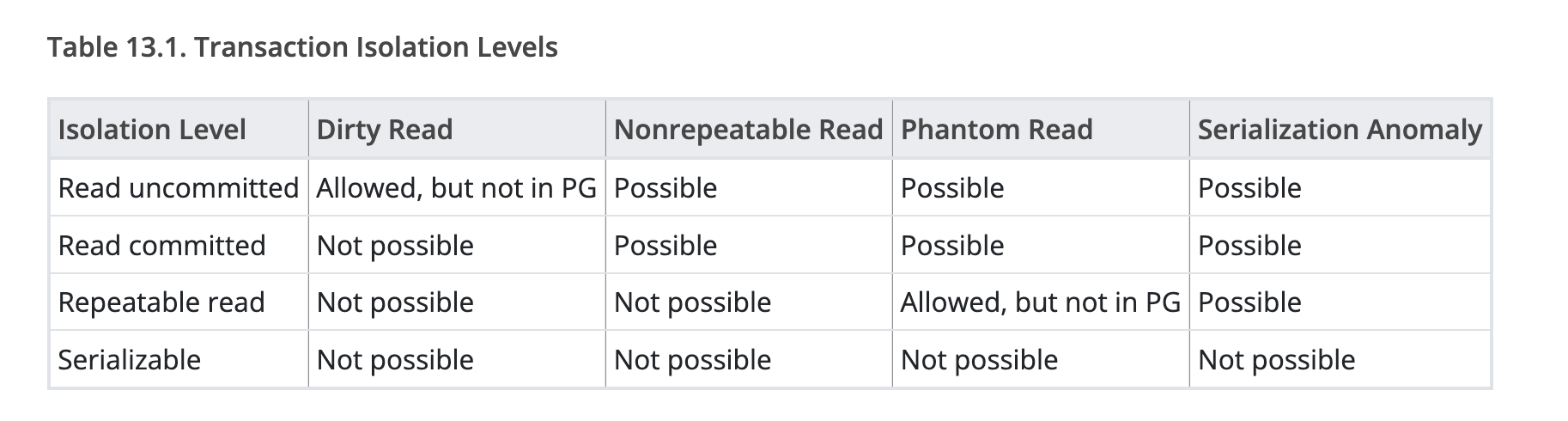
For SQL there is a standard, isolation levels are defined by the standard. The standard uses what “phenomena” is allowed to define the isolation level. This is like C++ has standards and each compiler implements it differently.
Honestly I sometimes still get confused by this table, I think the main reason is I don’t understand the “phenomena” by the bottom of my heart. Also it’s very hard to relate this to my day to day problems. I’m going to try to use the way that I hope someone would have explained this to me to write this post.
For now the things to understand is
- There is a SQL Standard about isolation levels. It is defined by what phenomena is allowed at each level.
- Each database implementation might implement it differently. Some might guarantee more than what the standards asks for. Also the standard doesn’t say if the implementation should use optimistic concurrency control or pessimistic concurrency control.
Optimistic Concurrency Control vs Pessimistic Concurrency Control
Before we go a bit further I think it’s nice to understand what is Optimistic Concurrency Control(OCC) vs Pessimistic Concurrency Control(PCC). In my understanding, OCC is where you are optimistic that there won’t be much conflicts, and if a conflict happens, you simply die and retry it. PCC is where you are pessimistic, and you believe that conflicts are gonna happen a lot, so you use locks to sort things out. When there is a conflict, you just wait for your turn.
The mistake I made was I thought PostgreSQL’s Serializable was pessimistic (it’s optimistic)
Example
Assume there is a bathroom in a building to be shared, an optimistic concurrency control scenario would be like there isn’t many people in the building, so we don’t even have a lock on the bathroom door, anyone could just walk in. Most of the times there won’t be anyone in there so you just walk in and use the bathroom, if you got unlucky and opened the door where someone else was in the bathroom, you come out (abort) and retry later.
Now assume that there are a lot of people in the building, it is highly likely that when you are using the bathroom someone wants to use it as well. We would add a lock to the bathroom door and have the key at the front desk, anyone who wants to use the bathroom has to wait at the front desk for the key then go to the bathroom. This is pessimistic concurrency control.
Now we have an understanding of optimistic concurrency control and pessimistic concurrency control let’s have a look at PostgreSQL’s isolation levels.
Let’s setup the environment
Right now postgres 18.3 is the latest version, let’s just use that.
Run docker pull postgres:18.3
Then let’s spin up the database with
docker run --name pg_isolation_test \
-e POSTGRES_USER=testuser \
-e POSTGRES_PASSWORD=testpass \
-e POSTGRES_DB=isolation_db \
-p 5432:5432 \
-d postgres:18.3
You can use docker ps to confirm that postgres is up and running
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
883e64ddfcbc postgres:18.3 "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:5432->5432/tcp, [::]:5432->5432/tcp pg_isolation_test
Now open two terminals. In both run docker exec -it pg_isolation_test psql -U testuser -d isolation_db
In any of them let’s use the following schema and test data
Now we should have the test table, test data, and two connections to try out things.
How to reason about transactions on paper
I found the most easy way to reason about transactions on paper is to use a two column table, where each column represents a single transaction and time goes from top to bottom. You could use excel or google sheets to try this out.
Given our test table, assume we are running the following SQL.
Two transactions trying to withdraw 100 from Alice’s account.
Would the SQL above drop the balance in database to below 0? Before we go and work it out on paper, I’d like to touch on one more thing.
Postgres uses MVCC, and the golden rule of MVCC is
Readers do not block Writers, and Writers do not block Readers. But Writers ALWAYS block Writers
When you run UPDATE, DELETE, SELECT FOR UPDATE they all trigger an exclusive row lock.
This is irrelevant to the isolation level.
Also the lock is only released when the transaction ends (COMMIT; or ROLLBACK;)
Read Committed Scenario On Paper: Tx1 and Tx2 both update before commit
See the table below and let’s walk through it

- At T3, Tx1
UPDATEthe balance to 0. And Tx1 locks Alice’s row because it is doing anUPDATE - At T4, Tx2 is blocked by the row lock
- At T5, Tx1 commits and Alice’s balance is set to 0. Also Tx1 releases the lock. This would unblock Tx2, where Tx2 would re-evalulate the where clause and since balance is 0 it fails the where clause hence update 0 rows
- At T6, Tx2 commits, nothing interesting happened since it updated 0 rows
So after this Alice’s balance is 0, records in database is still correct.
Read Committed Scenario On Paper: Tx1 commits before Tx2’s update
Let’s try to let Tx1 commit before Tx2’s statement runs

- At T3, Tx1 sets the balance to 0, Tx1 locks Alice’s row
- At T4, Tx1 commits, Tx1 releases Alice’s row lock
- At T5, Tx2 sees balance is 0 (since the isolation level is read committed), so where clause fails, note that since the
whereclause fails, Tx2 does not lock any rows - At T6, Tx2 commits but nothing changed
So after this Alice’s balance is 0, records in database is still correct.
How to try out transactions with a test database
No matter how much you convinced yourself on paper, without trying it out there is still a chance what you believed is wrong. I can’t tell how many times I was dead sure about something and it turns out to be wrong.
So let’s try to verify the above in our testing environment.
The Real Deal: Read Committed, Tx1 and Tx2 both update before commit
The Real Deal: Read Committed, Tx1 commits before Tx2’s update
The Four Isolation Levels in Postgres
Read Uncommitted
This is in the SQL standard but PostgreSQL does not allow this, even if you set the transaction isolation level to Read Uncommitted it acts as Read Committed due to MVCC. Honestly I don’t have enough knowledge of MVCC, but I could probably write something about it later when I learn about it.
For now I’ll put the “golden rule of MVCC” which I have above here again for emphasis.
Readers do not block Writers, and Writers do not block Readers. But Writers ALWAYS block Writers
Read Committed
Say you have a transaction with multiple selects and the isolation level is READ COMMITTED, if anything was committed by another transaction between your SELECTs, it would be showing in your up coming SELECT.
Every statement uses a new snapshot of the database.
[Gemini Review] Nuance: Query vs. Statement While we say “every statement,” technically Postgres takes a new snapshot at the start of every query. For simple commands, they are the same. But if you run a complex query with CTEs (Common Table Expressions) or a query that calls a
VOLATILEfunction multiple times, that entire query shares a single snapshot.
You would be able to see uncommitted results within your own transaction.
Single SQL statements all default to READ COMMITTED. Say you do a
UPDATE account SET balance=100 WHERE name='Alice', this by default runs asREAD COMMITTED, to change the default to saySERIALIZABLEyou would need toSET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE;
|
|
The actual tests also show how the UPDATE in our transaction got the locks
When would using READ COMMITTED isolation level in postgres cause issues?
READ COMMITTED is a noice default, but there are two cases where it falls short.
Application relying on stale data
When the application logic stores information in memory and instead of using SQL where clauses it uses a “stale” in memory value to check if it could update or not.
|
|
Here imagine two withdraw100() were ongoing at the same time without committing, both of them would withdraw the money and set the new balance to 0. Where we allowed withdrew for 200 but in the system it shows that the balance is 0.
To fix the above we could
- Do
SELECT FOR UPDATEand lock the row, pessimistic concurrency control. - Add a balance check in
UPDATE’sWHEREto make sure balance is100,tx.Exec(ctx, "UPDATE account SET balance = $1 WHERE name = 'Alice' AND balance=$2", newBalance, currentBalance)If updated rows is 0 then we retry. This is optimistic concurrency control. - Use
REPEATABLE READ, we will go through the details more but the gist is the transaction would fail if any of the following is true- Rows our transaction is writing to is different than the snapshot took at the beginning. (Technically in
REPEATABLE READthe snapshot is taken at the first non transactional control statement executes, first SELECT/UPDATE/DELETE etc,BEGINdoesn’t take the snapshot) - Rows our transaction is writing to is Locked by another transaction
- Rows our transaction is writing to is different than the snapshot took at the beginning. (Technically in
When SQL is doing statistics/aggregation calculation
Say in our example we want to calculate the SUM and AVG of balance in account table. Depend on how you write the SQL you might run into issues.
If you run ONE sql statement to get statistics it would always be accurate. Even if there is 1 million rows because in postgres when you run a SELECT statement it gives you the snapshot at that exact time, even if you are running with READ COMMITTED, you won’t read other committed messages because you are running ONE sql statement.
However if you run two selects using READ COMMITTED, you would run into issues.
Repeatable Read
Repeatable Read in postgres falls into optimistic concurrency control, meaning if you use this isolation level your transaction might fail and you would need to be ready to rerun it.
When transactions run in REPEATABLE READ postgres takes a snapshot at the beginning of the transaction.
A REPEATABLE READ transaction would fail if any of the following is true
- Rows our transaction is writing to is different than the snapshot took at the beginning. (Technically in
REPEATABLE READthe snapshot is taken at the first non transactional control statement executes, first SELECT/UPDATE/DELETE etc,BEGINdoesn’t take the snapshot) - Our transaction is waiting for a lock on a row, the moment the other transaction commits the change our transaction wakes up and dies. Note that even the other transaction committed the same value as the snapshot we still die.
If multiple transactions collide on the exact same row under REPEATABLE READ, it becomes a “One Winner, All Others Lose” scenario.
It is important to remember that a Repeatable Read transaction fails when it tries to modify a row and that row was changed since the snapshot.
Below I’m listing a few properties of repeatable read.
- The snapshot is taken at the first non transactional control statement executes
- The snapshot is the entire database, even if you only selected 1 row (note that this is an illusion but you can think of it as the entire database in your mind)
- Reads in a repeatable read won’t be affected by commits by other transactions
- Postgres repeatable read won’t get newly inserted rows after the snapshot is taken
|
|
After the properties let’s check out cases where your Repeatable Read would abort
- In the repeatable read transaction if you write to a row but that row was committed by another transaction.
|
|
- In the repeatable read transaction if you are waiting for a lock of a row but that row was changed by another transaction. As long as the other transaction updated the value(doesn’t even need to be different than snapshot, could be updated to the same value), it would kill the waiting transaction. In short it hang -> wakeup -> dies
|
|
Where Repeatable Read passes but it’s wrong
Let’s have a look where repeatable read passes but the result isn’t correct. The famous example is the oncall doctor example. Note that we are not using database constraints. Given the following table and data
Right now both Alice and Bob are on call. The business rule is: at any given time there must be at least one doctor on call.
Now let’s see the following scenario

This would pass under repeatable read, but the final result is all doctors are not on call.
The reason this is passing under repeatable read is both transactions wrote to different rows and those rows didn’t change.
- Tx1 wrote to Alice’s row which passes the snapshot check
- Tx2 wrote to Bob’s row which passes the snapshot check
We’ll see how serializable can help to solve this.
Serializable
I’ve always been confused about the word “Serializable” and why/how is it related to database isolation levels.
The strict definition is
A schedule of concurrent transactions is “Serializable” if its final outcome (the state of the data) is mathematically identical to the outcome that would have been produced if those exact same transactions had been run strictly one at a time, in some sequential order.
In other words this means as long as there exists one sequential order of the transactions in play that could produce the same final result as the actual result then the transactions are serializable.
When multiple transactions are running concurrently it might yield different results, for them to be serializable, as long as the actual final outcome could be achieved by one sequential execution order then the transactions are serializable.
The above is very important, assume that we have two transactions Tx1, Tx2. When they run concurrently there might be two possible final results, resultA and resultB. Among them assume resultA can be achieved by running Tx1 and Tx2 in a specific order, but resultB can not be achieved by any sequential order of Tx1 and Tx2. This would result in transactions passing when the final result is resultA and transactions failing when the final result is resultB. Meaning that the same transcations running in serialization may or may not trigger the serialization error based on how they were executed.
Now let’s (1) look at a real example and (2) think more about how can this confusing definition help us in practice. Like when would I know if I should mark my isolation level serializable.
For (1), let’s check the doctor example again
There are two transactions
- Tx1 which tries to take Alice off oncall only if after that there is at least one other doctor on call.
- Tx2 which tries to take Bob off oncall only if after that there is at least one other doctor on call.
The final result is

Had we run these transactions one by one can we achieve this result?
The answer is no
- If we run Tx1 first and commit, Tx2 won’t let Bob leave on call because he is the last doctor on call.
- If we run Tx2 first and commit, Tx1 won’t let Alice leave on call because she is the last doctor on call.
So here we see the actual final result is in a state where no possible sequential execution of Tx1 and Tx2 could achieve, hence these two transactions are not serializable.
When these two transactions are ran under serializable, the first one committed would pass and the other one won’t be able to commit.
[Gemini Review] Nuance: Who actually gets killed? Saying “the first one to commit wins” is a simplification. Under the hood, Postgres’s SSI attempts to abort the transaction that causes the least amount of wasted work. It specifically looks to kill the “pivot” transaction in a conflict. Depending on the timing of locks and reads, Postgres might abort the first transaction that tries to commit, or it might kill a transaction mid-flight before a commit is even attempted.
Let’s see this in action so you know I’m not capping.
The transaction that tries to remove Alice from on call
The transaction that tries to remove Bob from on call
This feels like “some sort of cycle happened” and postgres caught it. The following is a way for you to be able to look at a few transactions and determine in your mind (or on paper) if the transactions are serializable in postgres. Just bear with me and I promise I’ll explain it later.
- If there exists an ongoing transaction, you create a node in the graph
- If a transaction Tx1 reads from a row, and another transaction writes to the same row, draw an edge from Tx1 to Tx2
- If a cycle forms in the graph, then these transactions are not serializable
Let’s walk through the doctor on call example on paper.

- At T2, there exists two serializable transactions in the system. So we draw two nodes in the graph. No edges yet
- At T3, Tx1 read from two rows, the Alice row and the Bob row. No edges yet
- At T4, Tx2 read from two rows, the Alice row and the Bob row. No edges yet
- At T7, Tx1 write to the Alice row, we know that Tx2 read from Alice row, so we draw a directed edge from Tx2 to Tx1. Even if we have edges there are no cycles yet
- At T8, Tx2 write to the Bob row, we know that Tx1 read from Bob row, so we draw a directed edge from Tx1 to Tx2. Now we have a cycle. (Tx1 <-> Tx2), hence the transactions are not serializable.

The graph we created above is called Precedence Graph in database theory. The actual technique postgres used to implement serializable is Serializable Snapshot Isolation, this is also known as SSI.
[Gemini Review] Deep Dive: Dangerous Structures and False Positives While thinking about “cycles” is the mathematically correct way to understand serializability, actually traversing a massive graph of concurrent transactions to find cycles is too slow for a database. Instead, Postgres looks for a specific heuristic called a “dangerous structure” (specifically, two consecutive read-write conflicts:
T1 -rw-> T2 -rw-> T3). Because this is a heuristic, Postgres will sometimes abort a transaction that matches this pattern even if a full cycle never actually formed. SSI trades perfect precision for performance, meaning it occasionally yields “false positives” and kills perfectly safe transactions.
One other way to think about serializable in postgres is
In postgres
Serializable == REPEATABLE READ + Serializable Snapshot Isolation
Hope you haven’t forgot about (2) “when do I actually need serializable?”.
The answer is whenever your need to read and write based on the results of read you should consider using serializable. I used the word consider here because a lot of problems could be solved by Locks and Constraints. You don’t always need to slap on serializable to achieve your goal.
SSI only works on transactions that run under the SERIALIZABLE isolation level
One thing to be careful is that the graph cycle check algorithm we just went through above only applies when transactions are running under serializable isolation level. In the doctor on call example, if one transaction runs in serializable and the other runs in repeatable read, we would still get to the no one on call final state.
The reason is because the read/write tracking and edge drawing from read to write only tracks transactions that are running in serializable isolation level. If a transaction is not running in serializable, it is invisible to SSI. Let’s see this in action.
ww, wr, rw
If you look at the actual error that was thrown when I was trying to commit the serializable transaction you would see
ERROR: could not serialize access due to read/write dependencies among transactions
Why does it say “read/write”? Why isn’t this “write/read”? Are there any implications of this?
Turns out there actually is. We just mentioned that the underlying theory of SSI is Precedence Graph. In Precedence Graph there are three cases where we would draw an edge from one transaction to the other. The three cases are
- write/write: Tx1 writes a row first and then Tx2 writes the same row
- write/read: Tx1 writes a row first and then Tx2 reads the same row
- read/write: Tx1 reads a row first and then Tx2 writes the same row
Now there are three questions
- What is the difference between read/write and write/read again?
- Why isn’t there a read/read conflict?
- Why in the algorithm above you only draw an edge when read/write happened?
For (1), the difference between read/write and write/read is the order. read/write means for the same row Tx1 read it first and Tx2 wrote to it. Where as write/read means for the same row Tx1 wrote first then Tx2 read from it.
The answer of (2) is kinda trivial, read/read does happen but it won’t affect the final result hence the transactions are by definition serializable.
Things are more interesting when we look at (3).
Postgres’s SSI only tracks read/write conflicts. The reason is because write/write and write/read are handled by different mechanisms.
Remember this one liner?
In postgres serializable == repeatable read + SSI
When you run a transaction under serializable, it has all the properties of repeatable read. And it turns out that repeatable read + locks can handle both write/write and write/read. This is the reason why SSI only cares about read/write.
Let’s look at write/write.
In postgres write/write is handled by locks, we’ve seen this in repeatable read hang -> wakeup -> dies.
In the repeatable read transaction if you are waiting for a lock of a row but that row was changed by another transaction. As long as the other transaction updated the value(doesn’t even need to be different than snapshot, could be updated to the same value), it would kill the waiting transaction. In short it hang -> wakeup -> dies
Now lets look at write/read.
A write/read happens when Tx1 first writes and Tx2 reads from the same row, but if you scroll up a bit you would see that in repeatable read postgres takes one snapshot for the entire transaction. When Tx2 reads after Tx1 wrote it actually reads from the snapshot, so whatever Tx1 wrote doesn’t really matter to Tx2.
With this sorted out all is left for SSI to solve is read/write.
Hence why we only draw the directed edge when there is a read/write.
Further things to think about
At this point we can reason about transactions with abstractions like “snapshot” and “precedence graph”, but all these are hard to actually implement. There also exists many other questions to learn about, I’ll probably try to learn them at some point, but for now I’m just listing them as baits for you to be curious.
- What exactly is MVCC? How exactly does it work in postgres?
- How does postgres actually get the entire snapshot for a single repeatable read transaction?
- How does postgres keep track of the precedence graph effectively?
- How does postgres do cycle checks of the precedence graph so fast?
- How does other databases handle repeatable read and serialization?
- For databases that has Read Uncommitted (Microsoft SQL Server), why is it the case?
- What does MySQL or Microsoft SQL Server guarantee for repeatable read and serialization?
- How does MySQL or Microsoft SQL Server handle repeatable read and serialization? Can you see why/how the implementation relates to the guarantee they provide?